People tend to forget about disaster recovery when setting up a project.
Disaster recovery, as performance, security and usability should be by design.
Some will argue that disaster recovery is part of security, this is not the point here, and I agree with them.
This great tool made by @Neal Agarwal on his wonderful https://neal.fun/ website is a good opportunity to have a few word on disaster recovery, why it matters and what to do.
What if …
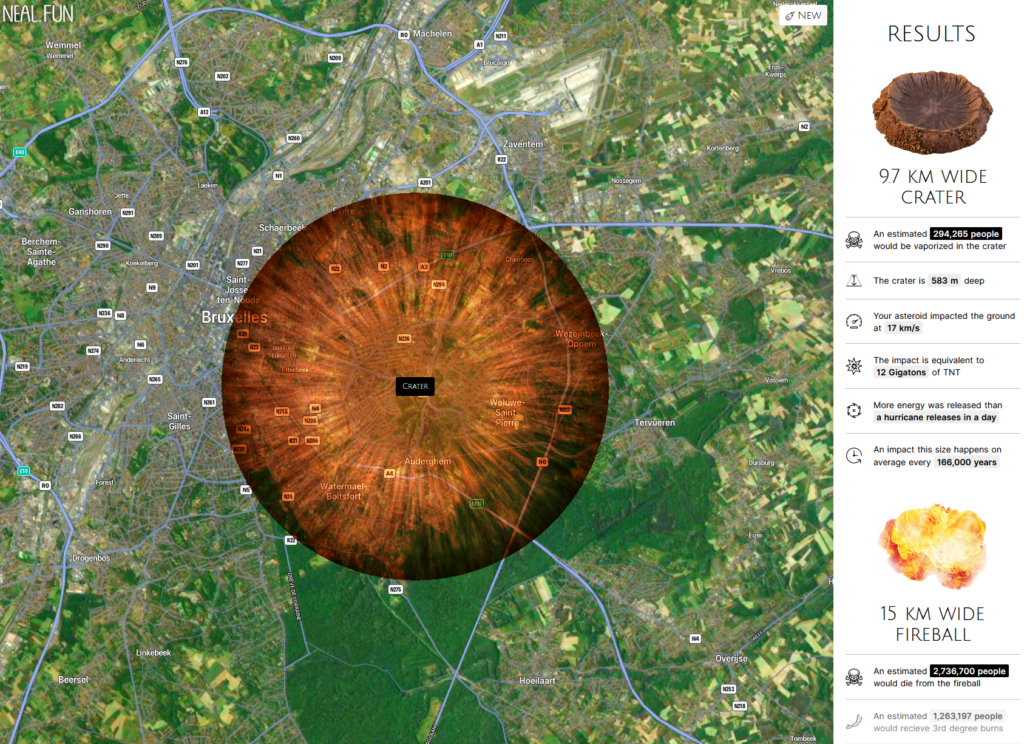
What if an asteroid hit Brussels? Well you will say, that we will probably have something better to do than having a website online.
True! A thousand times true!
But what if your site and apps are the one from the national broadcaster? We tend to forget crisis situation such as war, terrorism, pandemic and what the people from the other side of the sea call “Act of God”.
What will people do when all communication means are out of business? How will they know what to do?
Will everyone run for his life? And then? Help people? How? Where?
In peace time, no one care and everyone think that happiness will last forever. And then reality hit us right in the face!
When working in the past for a telecom operator we have though about this and create some plan with several levels of disaster such has minor, medium, major. Then we try to see in the past, in the history some example of minor, medium and major to illustrate and to align people. And after that we add percentage of such a thing to happen. Again based on past occurrences …
And 9/11 hit us hard in the face. Suddenly everyone turned the TV again, to watch CNN… and cry. Server went down because no one could believe and people where checking the information… at that time it was small server, small data center… but still.
As from that point things started to change.
For the telecom operator we had to create a full disaster recovery system, fully redundant and eventually every one was ready to spend money on it. It was necessary. And because of time proximity with the event, it was the number #1 priority.
2 Sites – Dual infrastructure – Master/Slave
The plan we decided to follow back then was a dual infrastructure (fully duplicated) on two sites distant from each other from about 34 km (~21 Miles).
Why not further? Because the needed space and the fiber was there already and we needed a lot of fiber to permanently replicate the content. Also we needed to have the fiber owned by us and not a sub contractor so it will cost less. You will probably say that it’s also important to have multiple lines. While that’s true we will cover that later.
We were in the years 2K the start of the 2Ks and we were providing internet and cell phone networks for millions of people, so we didn’t have any money issue, only decisions to take.
Plan
Two sites, double every servers, have backup power sources on the two sites, double air conditioning, double spare parts on every site, double team to maintain on site (it’s more or less technician that can do small operation on the server such has moving them and plugging them from one rack to another one, not the full ops team).
A year to set everything in place was an achievable deadline.
A data replication process and service replication process for every new project.
Do
I was not working on the telecom side, I was working on the website team. So we had way less hard problems then the pure telecom teams which where in charge of ensure the whole internet and cell communication should still work in case of a disaster.
For the websites part we used already on one site a database with Master and Slave. What we had to do is simply extending this notion on slave across a second site.
Mysql and then MariaDB were perfect candidate for this as it is almost built in and very well documented at the time. It was already used as all our reading (aka SELECT) were done on several slaves DB while our writing (aka INSERT/UPDATE/MERGE/DELETE…) were queued on one and only master.
The point is that know we had two master and two groups of slaves.
How did we address the switch from one to the other site back then? Well simply by using DNS server that will re-route the traffic to a new entry.
The servers were identical (I will come back to that point later on again) same memory, same hard drive, same hardware, same routers, same cables, same UPS, same softwares… they were mirrors only not totally synchronized and to ensure speed we used the Mysql way to replicate to Slave and because of the transactional model it will be replicated to all servers.
What we were using is now called “Replication DB Cluster”.
The difficulty we had at the time were the db modification, indeed when you create a new table, and change it at some point because the model did not fit or you found issue. Or simply because we created a stored procedure that increment something on every action…
The solution we found and it was linked to the emergence of version control system, was to move all the code out of the database. So we removed all the stored procedure, all the triggers and put all the business logic in the library that were used by the software. There was just one source of truth: the library. No more dark magic handled by a db engineer that vaguely remember that there is this stored procedure somewhere that indeed did update some fields …
Problem solved! … Not yet. Now the web front.
The web front must be duplicated as well. So the idea was to have twice the hardware there also, but because at the time we added a lot of libraries or did a lot of language and service upgrade to use this experimental wonderful approach to create object in the dev version that we absolutely needed! It was complex.
The approach we choose was by documenting everything. So we started with a wiki like way of documenting installation script, and the ops team kept the document up to date and once a week applied everything in prod… and crashed it…
So we decided to have ITT, UAT and PROD… InTegration Testing, User Acceptance Testing and PRODuction for the end user.
So we could run our process and copy paste every line of the documentation in the terminal to ensure that we did exactly the same thing and it wasn’t crashing. We still were keeping our breath when everything was fine on ITT, UAT and it was time for the PROD to be upgraded.
But we managed it this way… later on the document we were using moved from a wiki and from document to BASH script and code versioning… this has been called Ops Automation and is now called DevOps I think.
But that true that we were hand in hand, dev and ops together into this.
We also started with the same logic creating standard local development server (with the database and everything).
Just the year after we added a post hook in the centralized version control system that will automatically put the code on the entire platform (both sites) after succeeding some anti-regression test. This is now called CI/CD.
Check
That’s the most fun part. When you unplug a cable and see what’s going on.
The first test we did where within each sub network, to ensure that both site where working properly. Then we hit the big red button … of the phone and which was green to call the technician to unplug a power cable.
And we waited … and nothing happened, the DNS were way too slow to switch, the server which was using SNMP and listen to it wasn’t tested before hand and didn’t trigger the DNS switch. So we had the opportunity to test the manual switch procedure (which is also important to test anyway). And this one was working but because we did update the document after I think we missed some information any way.
So we added load balancing server (reverse proxy) in front of everything and the load balancing server were in charge of monitoring the heart beat of sub server to automatically move the traffic from one to the other.
So back to Plan and Do … yes. And after several iterations, it was all setup.
We had twice a year a disaster recovery test and we planned it, and we did it. I think it is still done today. Twice a year.
Yeah but now with the cloud, it’s ok…
Well yes and no.
A few years later, when working for the public broadcaster we had to setup disaster recovery for online video streaming. And while moving some element to the cloud, and because you are a public broadcaster and may publish message not aligned with some cloud provider you will need to think about a cloud infrastructure AND a server infrastructure as backup or at least a multi cloud infrastructure. Which is also quite hard to maintain … a bit less with stuff like Rancher, Docker and Kubernetes but still not that easy.
Act
Acting is ensuring that this will never happen again anymore and that we have put in place some mechanism to avoid any unforeseen situation.
The process for “every new project” and the document that were created and that must be filled prior to start anything is an act that allow the project to be tough of with disaster recovery by design.
The twice a year big switch off are also part of the ACT.
The source controlled documentation and server installation in also part of the ACT because it change as from “now” the way everything is done.
Actually the ACT is putting in place a process that will ensure that disaster recovery is by design.
Major?
The “fun” part was to make everyone agrees on what is major, medium and minor.
I had this exercise while working for the national broadcaster.
A Major issue is: War, government down, riot and revolt but also simply some heavy equipment cutting the main streaming internet line.
Again history helps us find track of this kind of issues. We remember all the disaster from tornado to earthquakes, from extreme party elections rules changes to war.
History shows us that a telecom operator or a public media broadcaster have to above all things, support the communication, interconnection and access to the information to every one. Will this information be a single page explaining where to go, where to escape, where to gather, like a message repeatedly sent through radio.
It’s also important to think wide enough. Do we still need to forbid multi-cast or board-cast in such a situation? The TCP/IP protocol was made for disaster recovery. It was built to be distributed.
So yes, I think an asteroid crashing in Brussels should also be considered as a major issue.
Anecdotes
- While installing duplicate hardware and because we ordered a lot of hardware, once we had two Ethernet cards with the same factory mac address connected on the same network. It took us about two days to find out, and it’s after plugin, in and out every server that we isolated the one with the issue and had the idea to search for mac addresses … The process of server installation was adapted accordingly: Do a MAC address lookup prior to connect the server to the network.
- The heavy equipment cutting a line can sometimes be: the cleaning guy was looking for a power outlet to plug the vacuum cleaner…
What’s your experience and anecdotes with disaster recovery?